Jay Taylor's notes
back to listing indexHow to resolve unassigned shards in Elasticsearch
[web search] Last updated: April 10, 2018
Last updated: April 10, 2018In Elasticsearch, a healthy cluster is a balanced cluster: primary and replica shards are distributed across all nodes for durable reliability in case of node failure.
But what should you do when you see shards lingering in an UNASSIGNED state?
Before we dive into some solutions, let’s verify that the unassigned shards contain data that we need to preserve (if not, deleting these shards is the most straightforward way to resolve the issue). If you already know the data’s worth saving, jump to the solutions:
- -Shard allocation is purposefully delayed
- -Too many shards, not enough nodes
- -You need to re-enable shard allocation
- -Shard data no longer exists in the cluster
- -Low disk watermark
- -Multiple Elasticsearch versions
The commands in this post are formatted under the assumption that you are running each Elasticsearch instance’s HTTP service on the default port (9200). They are also directed to localhost, which assumes that you are submitting the request locally; otherwise, replace localhost with your node’s IP address.
Pinpointing problematic shards
Elasticsearch’s cat API will tell you which shards are unassigned, and why:
curl -XGET localhost:9200/_cat/shards?h=index,shard,prirep,state,unassigned.reason| grep UNASSIGNED
Each row lists the name of the index, the shard number, whether it is a primary (p) or replica (r) shard, and the reason it is unassigned:
constant-updates 0 p UNASSIGNED NODE_LEFT node_left[NODE_NAME]
If you’re running version 5+ of Elasticsearch, you can also use the cluster allocation explain API to try to garner more information about shard allocation issues:
curl -XGET localhost:9200/_cluster/allocation/explain?pretty
The resulting output will provide helpful details about why certain shards in your cluster remain unassigned:
{
"index" : "testing",
"shard" : 0,
"primary" : false,
"current_state" : "unassigned",
"unassigned_info" : {
"reason" : "INDEX_CREATED",
"at" : "2018-04-09T21:48:23.293Z",
"last_allocation_status" : "no_attempt"
},
"can_allocate" : "no",
"allocate_explanation" : "cannot allocate because allocation is not permitted to any of the nodes",
"node_allocation_decisions" : [
{
"node_id" : "t_DVRrfNS12IMhWvlvcfCQ",
"node_name" : "t_DVRrf",
"transport_address" : "127.0.0.1:9300",
"node_decision" : "no",
"weight_ranking" : 1,
"deciders" : [
{
"decider" : "same_shard",
"decision" : "NO",
"explanation" : "the shard cannot be allocated to the same node on which a copy of the shard already exists"
}
]
}
]
}
In this case, the API clearly explains why the replica shard remains unassigned: “the shard cannot be allocated to the same node on which a copy of the shard already exists”. To view more details about this particular issue and how to resolve it, skip ahead to a later section of this post.
If it looks like the unassigned shards belong to an index you thought you deleted already, or an outdated index that you don’t need anymore, then you can delete the index to restore your cluster status to green:
curl -XDELETE 'localhost:9200/index_name/'
If that didn’t solve the issue, read on to try other solutions.
Reason 1: Shard allocation is purposefully delayed
When a node leaves the cluster, the master node temporarily delays shard reallocation to avoid needlessly wasting resources on rebalancing shards, in the event the original node is able to recover within a certain period of time (one minute, by default). If this is the case, your logs should look something like this:
[TIMESTAMP][INFO][cluster.routing] [MASTER NODE NAME] delaying allocation for [54] unassigned shards, next check in [1m]
You can dynamically modify the delay period like so:
curl -XPUT 'localhost:9200/<INDEX_NAME>/_settings' -d
'{
"settings": {
"index.unassigned.node_left.delayed_timeout": "30s"
}
}'
Replacing <INDEX_NAME> with _all will update the threshold for all indices in your cluster.
After the delay period is over, you should start seeing the master assigning those shards. If not, keep reading to explore solutions to other potential causes.
Reason 2: Too many shards, not enough nodes
As nodes join and leave the cluster, the master node reassigns shards automatically, ensuring that multiple copies of a shard aren’t assigned to the same node. In other words, the master node will not assign a primary shard to the same node as its replica, nor will it assign two replicas of the same shard to the same node. A shard may linger in an unassigned state if there are not enough nodes to distribute the shards accordingly.
To avoid this issue, make sure that every index in your cluster is initialized with fewer replicas per primary shard than the number of nodes in your cluster by following the formula below:
N >= R + 1
Where N is the number of nodes in your cluster, and R is the largest shard replication factor across all indices in your cluster.
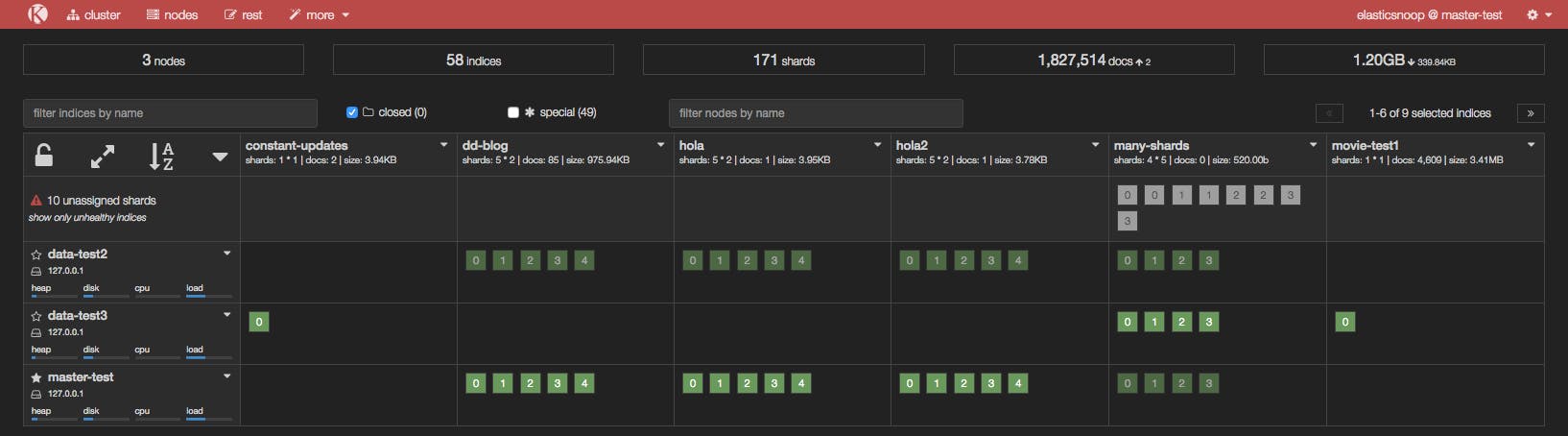
In the screenshot below, the many-shards index is stored on four primary shards and each primary has four replicas. Eight of the index’s 20 shards are unassigned because our cluster only contains three nodes. Two replicas of each primary shard haven’t been assigned because each of the three nodes already contains a copy of that shard.