Jay Taylor's notes
back to listing indexGitHub - ArchiveBox/ArchiveBox: 🗃 Open source self-hosted web archiving. Takes URLs/browser history/bookmarks/Pocket/Pinboard/etc., saves HTML, JS, PDFs, media, and more...
[web search] Open-source self-hosted web archiving.
Open-source self-hosted web archiving.
▶️ Quickstart | Demo | GitHub | Documentation | Info & Motivation | Community | Roadmap
"Your own personal internet archive" (网站存档 / 爬虫) curl -sSL 'https://get.archivebox.io' | sh

ArchiveBox is a powerful, self-hosted internet archiving solution to collect, save, and view sites you want to preserve offline.
You can set it up as a command-line tool, web app, and desktop app (alpha), on Linux, macOS, and Windows (WSL/Docker).
You can feed it URLs one at a time, or schedule regular imports from browser bookmarks or history, feeds like RSS, bookmark services like Pocket/Pinboard, and more. See input formats for a full list.
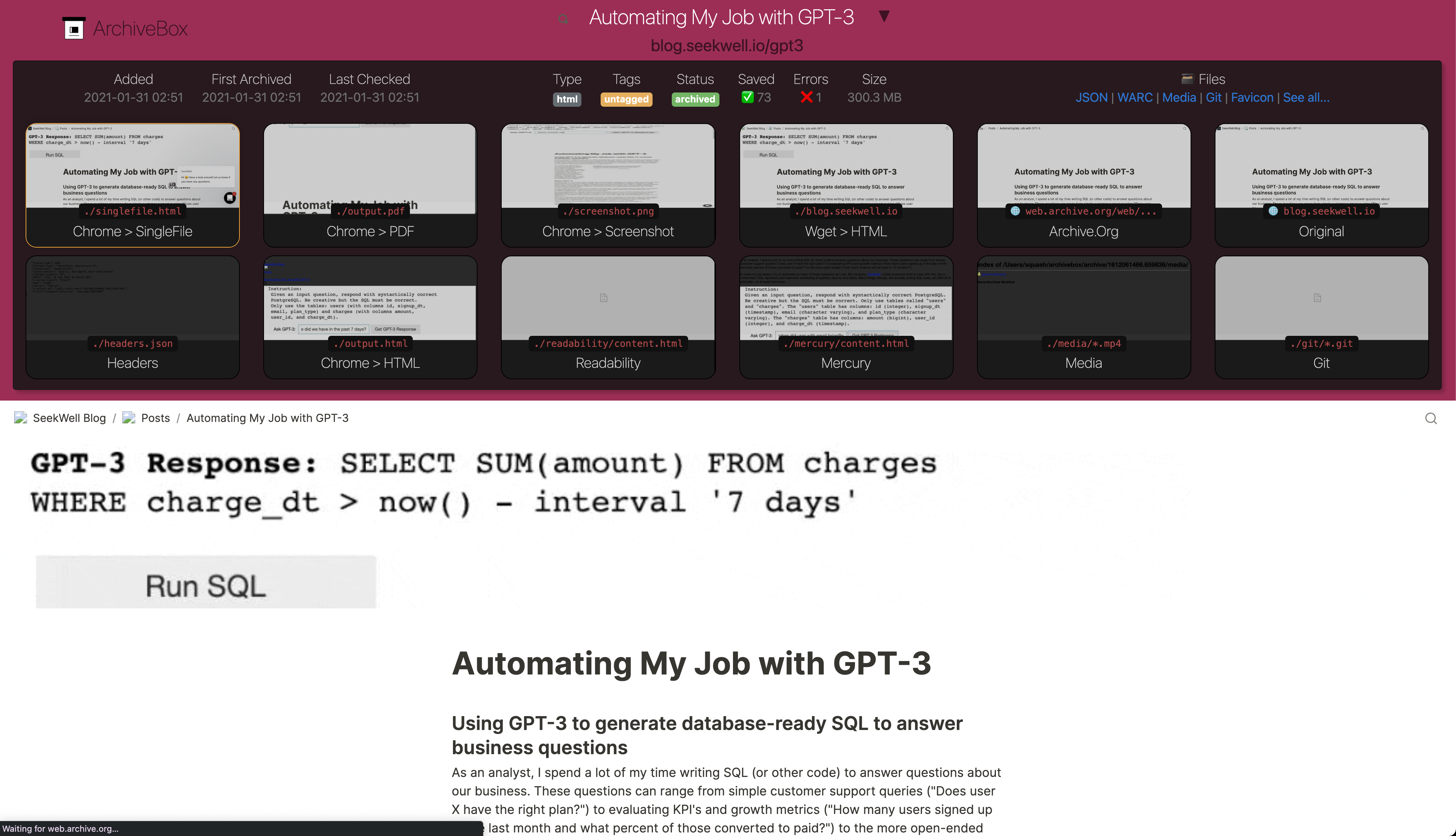
It saves snapshots of the URLs you feed it in several formats: HTML, PDF, PNG screenshots, WARC, and more out-of-the-box, with a wide variety of content extracted and preserved automatically (article text, audio/video, git repos, etc.). See output formats for a full list.
The goal is to sleep soundly knowing the part of the internet you care about will be automatically preserved in durable, easily accessible formats for decades after it goes down.

Get ArchiveBox with docker / apt / brew / pip3 / nix / etc. (see Quickstart below).
# Get ArchiveBox with Docker or Docker Compose (recommended) docker run -v $PWD/data:/data -it archivebox/archivebox:dev init --setup # Or install with your preferred package manager (see Quickstart below for apt, brew, and more) pip3 install archivebox # Or use the optional auto setup script to install it curl -sSL 'https://get.archivebox.io' | sh
Example usage: adding links to archive.
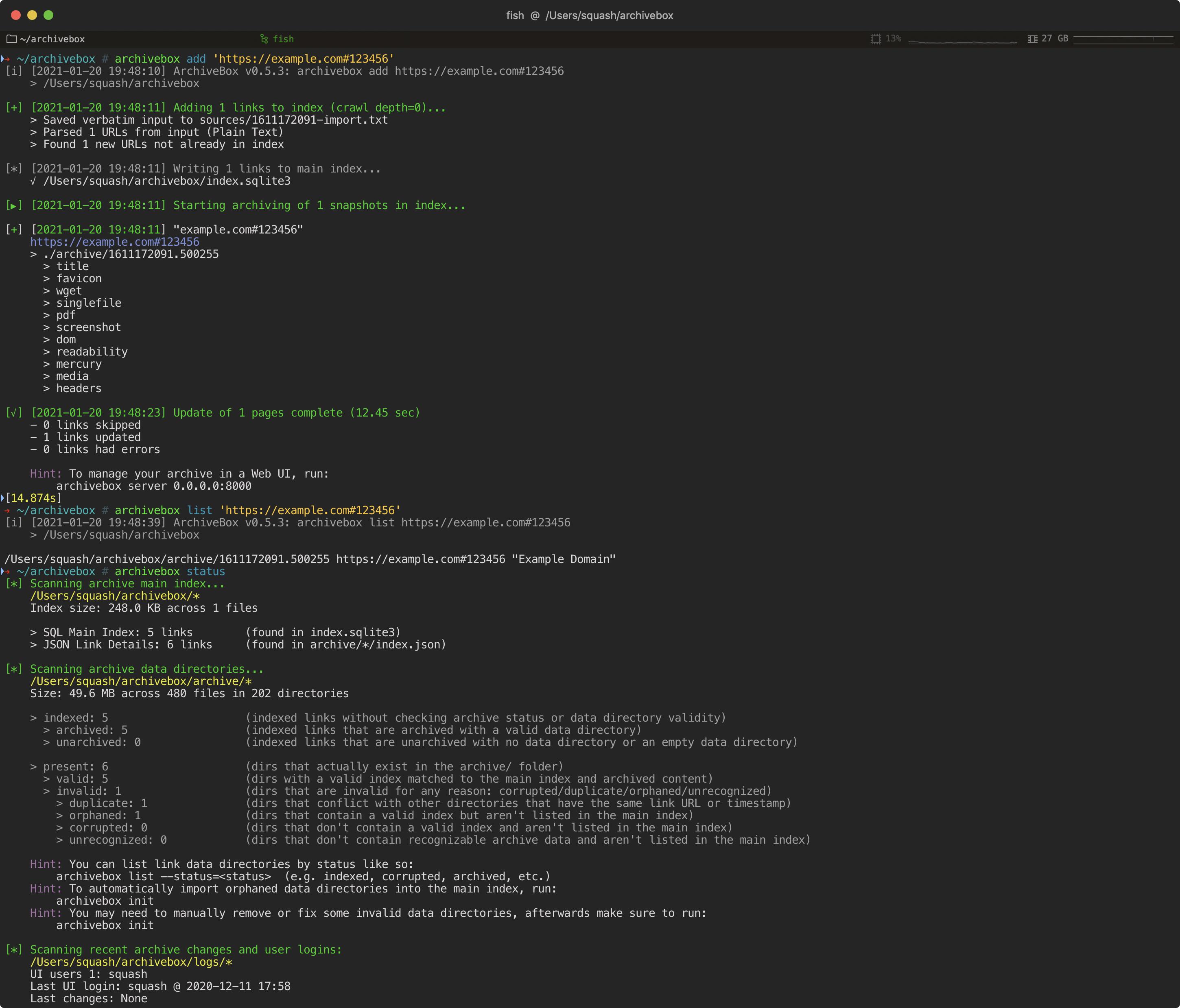
archivebox add 'https://example.com' # add URLs one at a time archivebox add < ~/Downloads/bookmarks.json # or pipe in URLs in any text-based format archivebox schedule --every=day --depth=1 https://example.com/rss.xml # or auto-import URLs regularly on a schedule
Example usage: viewing the archived content.
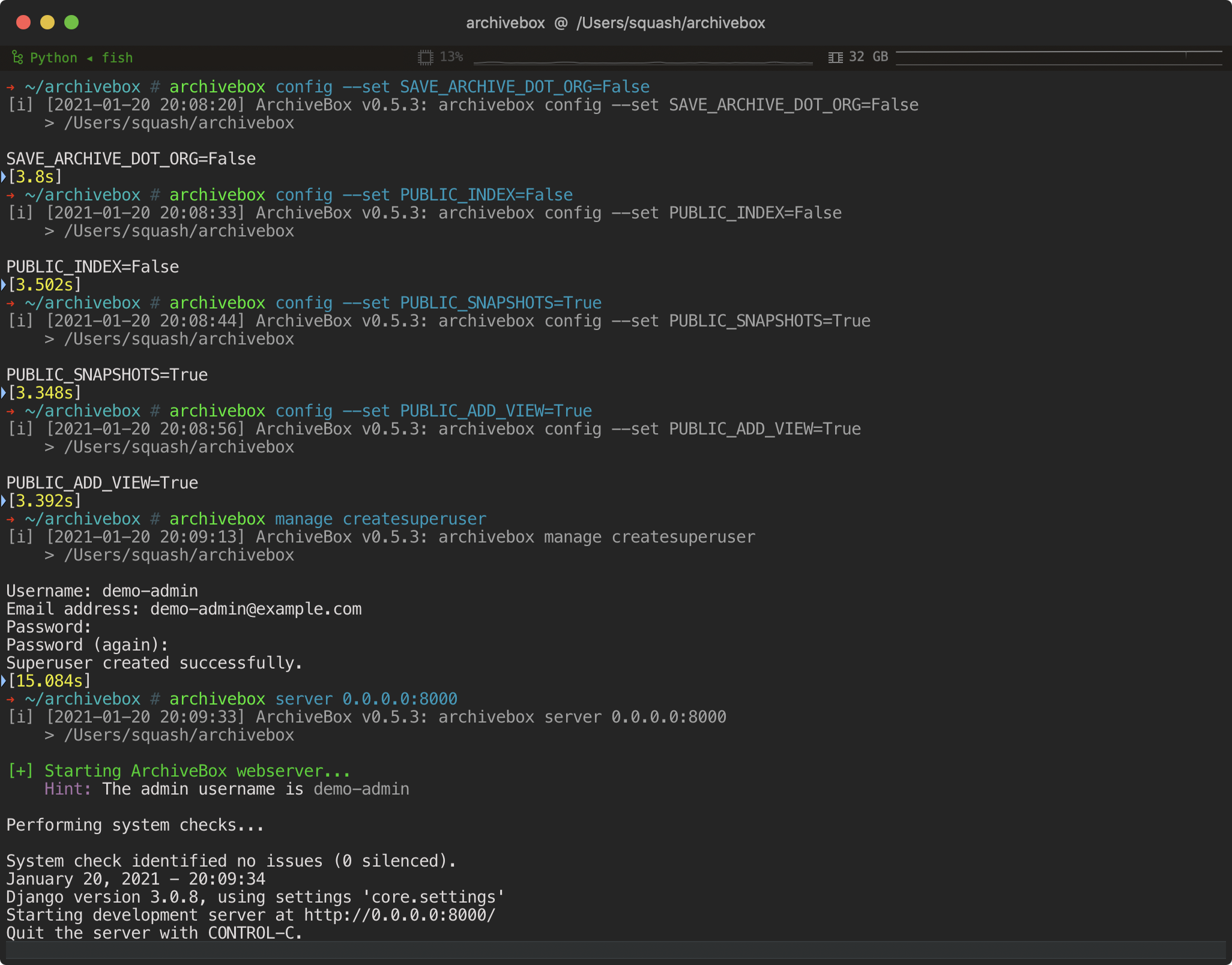
archivebox server 0.0.0.0:8000 # use the interactive web UI archivebox list 'https://example.com' # use the CLI commands (--help for more) ls ./archive/*/index.json # or browse directly via the filesystem







 . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . .
DEMO: https://demo.archivebox.io
Usage | Configuration | Caveats








The balance between the permanence and ephemeral nature of content on the internet is part of what makes it beautiful. I don't think everything should be preserved in an automated fashion--making all content permanent and never removable, but I do think people should be able to decide for themselves and effectively archive specific content that they care about.
Because modern websites are complicated and often rely on dynamic content,
ArchiveBox archives the sites in several different formats beyond what public archiving services like Archive.org/Archive.is save. Using multiple methods and the market-dominant browser to execute JS ensures we can save even the most complex, finicky websites in at least a few high-quality, long-term data formats.

 Community-maintained indexes of archiving tools and institutions.
Community-maintained indexes of archiving tools and institutions.
Web Archiving Software
Open source tools and projects in the internet archiving space.
Reading List
Articles, posts, and blogs relevant to ArchiveBox and web archiving in general.
Communities
A collection of the most active internet archiving communities and initiatives.
Check out the ArchiveBox Roadmap and Changelog
Learn why archiving the internet is important by reading the "On the Importance of Web Archiving" blog post.
Reach out to me for questions and comments via @ArchiveBoxApp or @theSquashSH on Twitter
Need help building a custom archiving solution?
✨ Hire the team that helps build Archivebox to work on your project. (@MonadicalSAS)
(They also do general software consulting across many industries)



 This project is maintained mostly in my spare time with the help from generous contributors and Monadical (✨ hire them for dev work!).
This project is maintained mostly in my spare time with the help from generous contributors and Monadical (✨ hire them for dev work!).
Sponsor this project on GitHub


✨ Have spare CPU/disk/bandwidth and want to help the world?
Check out our Good Karma Kit...
Footer
. . . . . . . . . . . . . . . . . . . . . . . . . . . .
DEMO: https://demo.archivebox.io
Usage | Configuration | Caveats
The balance between the permanence and ephemeral nature of content on the internet is part of what makes it beautiful. I don't think everything should be preserved in an automated fashion--making all content permanent and never removable, but I do think people should be able to decide for themselves and effectively archive specific content that they care about.
Because modern websites are complicated and often rely on dynamic content,
ArchiveBox archives the sites in several different formats beyond what public archiving services like Archive.org/Archive.is save. Using multiple methods and the market-dominant browser to execute JS ensures we can save even the most complex, finicky websites in at least a few high-quality, long-term data formats.
Community-maintained indexes of archiving tools and institutions.
Web Archiving Software
Open source tools and projects in the internet archiving space.
Reading List
Articles, posts, and blogs relevant to ArchiveBox and web archiving in general.
Communities
A collection of the most active internet archiving communities and initiatives.
Check out the ArchiveBox Roadmap and Changelog
Learn why archiving the internet is important by reading the "On the Importance of Web Archiving" blog post.
Reach out to me for questions and comments via @ArchiveBoxApp or @theSquashSH on Twitter
Need help building a custom archiving solution?
✨ Hire the team that helps build Archivebox to work on your project. (@MonadicalSAS)
(They also do general software consulting across many industries)
This project is maintained mostly in my spare time with the help from generous contributors and Monadical (✨ hire them for dev work!).
Sponsor this project on GitHub
✨ Have spare CPU/disk/bandwidth and want to help the world?
Check out our Good Karma Kit...
Footer
. . . . . . . . . . . . . . . . . . . . . . . . . . . .
DEMO: https://demo.archivebox.io
Usage | Configuration | Caveats
The balance between the permanence and ephemeral nature of content on the internet is part of what makes it beautiful. I don't think everything should be preserved in an automated fashion--making all content permanent and never removable, but I do think people should be able to decide for themselves and effectively archive specific content that they care about.
Because modern websites are complicated and often rely on dynamic content,
ArchiveBox archives the sites in several different formats beyond what public archiving services like Archive.org/Archive.is save. Using multiple methods and the market-dominant browser to execute JS ensures we can save even the most complex, finicky websites in at least a few high-quality, long-term data formats.
Community-maintained indexes of archiving tools and institutions.
Web Archiving Software
Open source tools and projects in the internet archiving space.
Reading List
Articles, posts, and blogs relevant to ArchiveBox and web archiving in general.
Communities
A collection of the most active internet archiving communities and initiatives.
Check out the ArchiveBox Roadmap and Changelog
Learn why archiving the internet is important by reading the "On the Importance of Web Archiving" blog post.
Reach out to me for questions and comments via @ArchiveBoxApp or @theSquashSH on Twitter
Need help building a custom archiving solution?
✨ Hire the team that helps build Archivebox to work on your project. (@MonadicalSAS)
(They also do general software consulting across many industries)
This project is maintained mostly in my spare time with the help from generous contributors and Monadical (✨ hire them for dev work!).
Sponsor this project on GitHub
✨ Have spare CPU/disk/bandwidth and want to help the world?
Check out our Good Karma Kit...
Footer
. . . . . . . . . . . . . . . . . . . . . . . . . . . .
DEMO: https://demo.archivebox.io
Usage | Configuration | Caveats
The balance between the permanence and ephemeral nature of content on the internet is part of what makes it beautiful. I don't think everything should be preserved in an automated fashion--making all content permanent and never removable, but I do think people should be able to decide for themselves and effectively archive specific content that they care about.
Because modern websites are complicated and often rely on dynamic content,
ArchiveBox archives the sites in several different formats beyond what public archiving services like Archive.org/Archive.is save. Using multiple methods and the market-dominant browser to execute JS ensures we can save even the most complex, finicky websites in at least a few high-quality, long-term data formats.
Community-maintained indexes of archiving tools and institutions.
Web Archiving Software
Open source tools and projects in the internet archiving space.
Reading List
Articles, posts, and blogs relevant to ArchiveBox and web archiving in general.
Communities
A collection of the most active internet archiving communities and initiatives.
Check out the ArchiveBox Roadmap and Changelog
Learn why archiving the internet is important by reading the "On the Importance of Web Archiving" blog post.
Reach out to me for questions and comments via @ArchiveBoxApp or @theSquashSH on Twitter
Need help building a custom archiving solution?
✨ Hire the team that helps build Archivebox to work on your project. (@MonadicalSAS)
(They also do general software consulting across many industries)
This project is maintained mostly in my spare time with the help from generous contributors and Monadical (✨ hire them for dev work!).
Sponsor this project on GitHub
✨ Have spare CPU/disk/bandwidth and want to help the world?
Check out our Good Karma Kit...
Footer
DEMO:
https://demo.archivebox.ioUsage | Configuration | Caveats
The balance between the permanence and ephemeral nature of content on the internet is part of what makes it beautiful. I don't think everything should be preserved in an automated fashion--making all content permanent and never removable, but I do think people should be able to decide for themselves and effectively archive specific content that they care about.
Because modern websites are complicated and often rely on dynamic content,
ArchiveBox archives the sites in several different formats beyond what public archiving services like Archive.org/Archive.is save. Using multiple methods and the market-dominant browser to execute JS ensures we can save even the most complex, finicky websites in at least a few high-quality, long-term data formats.
Community-maintained indexes of archiving tools and institutions.
Web Archiving Software
Open source tools and projects in the internet archiving space.
Reading List
Articles, posts, and blogs relevant to ArchiveBox and web archiving in general.
Communities
A collection of the most active internet archiving communities and initiatives.
Check out the ArchiveBox Roadmap and Changelog
Learn why archiving the internet is important by reading the "On the Importance of Web Archiving" blog post.
Reach out to me for questions and comments via @ArchiveBoxApp or @theSquashSH on Twitter
Need help building a custom archiving solution?
✨ Hire the team that helps build Archivebox to work on your project. (@MonadicalSAS)
(They also do general software consulting across many industries)
This project is maintained mostly in my spare time with the help from generous contributors and Monadical (✨ hire them for dev work!).
Sponsor this project on GitHub
✨ Have spare CPU/disk/bandwidth and want to help the world?
Check out our Good Karma Kit...
Footer
The balance between the permanence and ephemeral nature of content on the internet is part of what makes it beautiful. I don't think everything should be preserved in an automated fashion--making all content permanent and never removable, but I do think people should be able to decide for themselves and effectively archive specific content that they care about.
Because modern websites are complicated and often rely on dynamic content,
ArchiveBox archives the sites in several different formats beyond what public archiving services like Archive.org/Archive.is save. Using multiple methods and the market-dominant browser to execute JS ensures we can save even the most complex, finicky websites in at least a few high-quality, long-term data formats.
Community-maintained indexes of archiving tools and institutions.
Web Archiving Software
Open source tools and projects in the internet archiving space.
Reading List
Articles, posts, and blogs relevant to ArchiveBox and web archiving in general.
Communities
A collection of the most active internet archiving communities and initiatives.
Check out the ArchiveBox Roadmap and Changelog
Learn why archiving the internet is important by reading the "On the Importance of Web Archiving" blog post.
Reach out to me for questions and comments via @ArchiveBoxApp or @theSquashSH on Twitter
Need help building a custom archiving solution?
✨ Hire the team that helps build Archivebox to work on your project. (@MonadicalSAS)
(They also do general software consulting across many industries)
This project is maintained mostly in my spare time with the help from generous contributors and Monadical (✨ hire them for dev work!).
Sponsor this project on GitHub
✨ Have spare CPU/disk/bandwidth and want to help the world?
Check out our Good Karma Kit...
Footer
The balance between the permanence and ephemeral nature of content on the internet is part of what makes it beautiful. I don't think everything should be preserved in an automated fashion--making all content permanent and never removable, but I do think people should be able to decide for themselves and effectively archive specific content that they care about.
Because modern websites are complicated and often rely on dynamic content,
ArchiveBox archives the sites in several different formats beyond what public archiving services like Archive.org/Archive.is save. Using multiple methods and the market-dominant browser to execute JS ensures we can save even the most complex, finicky websites in at least a few high-quality, long-term data formats.
Community-maintained indexes of archiving tools and institutions.
Web Archiving Software
Open source tools and projects in the internet archiving space.
Reading List
Articles, posts, and blogs relevant to ArchiveBox and web archiving in general.
Communities
A collection of the most active internet archiving communities and initiatives.
Check out the ArchiveBox Roadmap and Changelog
Learn why archiving the internet is important by reading the "On the Importance of Web Archiving" blog post.
Reach out to me for questions and comments via @ArchiveBoxApp or @theSquashSH on Twitter
Need help building a custom archiving solution?
✨ Hire the team that helps build Archivebox to work on your project. (@MonadicalSAS)
(They also do general software consulting across many industries)
This project is maintained mostly in my spare time with the help from generous contributors and Monadical (✨ hire them for dev work!).
Sponsor this project on GitHub
✨ Have spare CPU/disk/bandwidth and want to help the world?
Check out our Good Karma Kit...
Footer
The balance between the permanence and ephemeral nature of content on the internet is part of what makes it beautiful. I don't think everything should be preserved in an automated fashion--making all content permanent and never removable, but I do think people should be able to decide for themselves and effectively archive specific content that they care about.
Because modern websites are complicated and often rely on dynamic content,
ArchiveBox archives the sites in several different formats beyond what public archiving services like Archive.org/Archive.is save. Using multiple methods and the market-dominant browser to execute JS ensures we can save even the most complex, finicky websites in at least a few high-quality, long-term data formats.
Community-maintained indexes of archiving tools and institutions.
Web Archiving Software
Open source tools and projects in the internet archiving space.
Reading List
Articles, posts, and blogs relevant to ArchiveBox and web archiving in general.
Communities
A collection of the most active internet archiving communities and initiatives.
Check out the ArchiveBox Roadmap and Changelog
Learn why archiving the internet is important by reading the "On the Importance of Web Archiving" blog post.
Reach out to me for questions and comments via @ArchiveBoxApp or @theSquashSH on Twitter
Need help building a custom archiving solution?
✨ Hire the team that helps build Archivebox to work on your project. (@MonadicalSAS)
(They also do general software consulting across many industries)
This project is maintained mostly in my spare time with the help from generous contributors and Monadical (✨ hire them for dev work!).
Sponsor this project on GitHub
✨ Have spare CPU/disk/bandwidth and want to help the world?
Check out our Good Karma Kit...
Footer

The balance between the permanence and ephemeral nature of content on the internet is part of what makes it beautiful. I don't think everything should be preserved in an automated fashion--making all content permanent and never removable, but I do think people should be able to decide for themselves and effectively archive specific content that they care about.
Because modern websites are complicated and often rely on dynamic content, ArchiveBox archives the sites in several different formats beyond what public archiving services like Archive.org/Archive.is save. Using multiple methods and the market-dominant browser to execute JS ensures we can save even the most complex, finicky websites in at least a few high-quality, long-term data formats.
Community-maintained indexes of archiving tools and institutions.
Open source tools and projects in the internet archiving space.
Articles, posts, and blogs relevant to ArchiveBox and web archiving in general.
A collection of the most active internet archiving communities and initiatives.
Need help building a custom archiving solution?
✨ Hire the team that helps build Archivebox to work on your project. (@MonadicalSAS)
(They also do general software consulting across many industries)
This project is maintained mostly in my spare time with the help from generous contributors and Monadical (✨ hire them for dev work!).
Sponsor this project on GitHub
✨ Have spare CPU/disk/bandwidth and want to help the world?
Check out our Good Karma Kit...
This project is maintained mostly in my spare time with the help from generous contributors and Monadical (✨ hire them for dev work!).
Sponsor this project on GitHub
✨ Have spare CPU/disk/bandwidth and want to help the world?
Check out our Good Karma Kit...